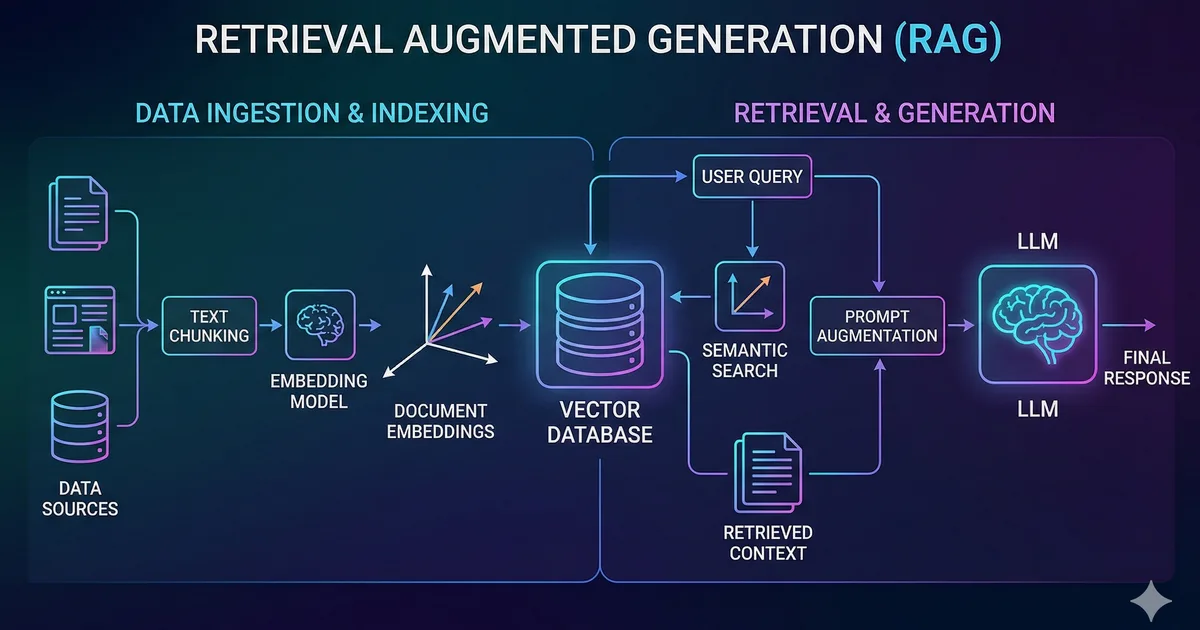
Qué es RAG?
RAG (Retrieval-Augmented Generation) es una técnica que combina la busqueda de información relevante con la generación de texto mediante un modelo de lenguaje. En lugar de confiar unicamente en el conocimiento interno del modelo, le proporcionamos contexto específico de nuestros propios datos.
Por qué necesitas RAG?
Los modelos de lenguaje tienen limitaciones importantes:
- Conocimiento desactualizado: Su entrenamiento tiene una fecha de corte
- Alucinaciones: Pueden generar información plausible pero incorrecta
- Sin datos privados: No conocen la documentación interna de tu empresa
RAG resuelve estos tres problemas al inyectar información relevante y actualizada directamente en el prompt.
Arquitectura de un sistema RAG
Un sistema RAG tiene tres componentes principales:
1. Ingesta de documentos
El primer paso es preparar tus documentos. Esto implica:
- Chunking: Dividir documentos largos en fragmentos manejables
- Embedding: Convertir cada fragmento en un vector numérico
- Almacenamiento: Guardar los vectores en una base de datos vectorial
2. Recuperacion (Retrieval)
Cuando el usuario hace una pregunta:
- Se convierte la pregunta en un embedding
- Se buscan los documentos más similares en la base de datos vectorial
- Se seleccionan los top-K documentos más relevantes
3. Generacion (Generation)
Los documentos recuperados se inyectan como contexto en el prompt del modelo de lenguaje, que genera una respuesta basada en esa información.
Tutorial: Construyendo un RAG desde cero
Vamos a construir un sistema RAG completo paso a paso usando TypeScript.
Paso 1: Preparar los documentos
Primero necesitamos dividir nuestros documentos en chunks. Una estrategia comun es dividir por párrafos con solapamiento:
interface Chunk {
id: string;
content: string;
metadata: {
source: string;
position: number;
};
}
function chunkText(
text: string,
chunkSize: number = 500,
overlap: number = 50
): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
const end = Math.min(start + chunkSize, text.length);
chunks.push(text.slice(start, end));
start += chunkSize - overlap;
}
return chunks;
}Paso 2: Generar embeddings
Los embeddings son representaciones numericas del significado del texto. Textos con significados similares tendrán vectores cercanos en el espacio vectorial.
Paso 3: Busqueda por similitud
La similitud coseno es la metrica más comun para comparar embeddings. Un valor de 1 indica textos identicos en significado, mientras que 0 indica que no tienen relacion.
Paso 4: Generar con contexto
Finalmente, enviamos la pregunta junto con los documentos recuperados al modelo de lenguaje.
Estrategias de chunking
La forma en que divides tus documentos tiene un impacto enorme en la calidad de los resultados.
| Estrategia | Ventaja | Desventaja |
|---|---|---|
| Tamano fijo | Simple de implementar | Puede cortar ideas a la mitad |
| Por párrafos | Preserva unidades logicas | Tamanos variables |
| Semántico | Mejor coherencia | Más complejo y costoso |
| Recursivo | Balance entre coherencia y tamaño | Requiere configuración |
Recomendaciones prácticas
- Usa chunks de 200-500 tokens para documentación técnica
- Agrega solapamiento de 50-100 tokens para mantener contexto
- Incluye metadata (título de sección, fuente) en cada chunk
- Experimenta con diferentes tamaños para tu caso de uso
Bases de datos vectoriales
Para producción, necesitas una base de datos vectorial dedicada en lugar de buscar en memoria.
Opciones populares
- pgvector: Extension de PostgreSQL. Ideal si ya usas Postgres
- ChromaDB: Open source, fácil de configurar, perfecto para prototipos
- Pinecone: Servicio gestionado, escalable, sin infraestructura que mantener
- Qdrant: Open source, alto rendimiento, API REST
Ejemplo con pgvector
-- Crear tabla con columna vector
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding vector(1536),
metadata JSONB
);
-- Crear índice para busqueda rápida
CREATE INDEX ON documents
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- Buscar documentos similares
SELECT content, 1 - (embedding <=> $1::vector) AS similarity
FROM documents
ORDER BY embedding <=> $1::vector
LIMIT 5;Evaluacion de tu RAG
Medir la calidad de un sistema RAG es fundamental. Las metricas clave son:
- Precision del retrieval: Los documentos recuperados son relevantes?
- Recall: Se recuperan todos los documentos relevantes?
- Fidelidad de la respuesta: La respuesta se basa en el contexto proporcionado?
- Relevancia de la respuesta: La respuesta contesta la pregunta?
Errores comunes y como evitarlos
- Chunks demasiado grandes: El modelo se pierde en contexto irrelevante
- Chunks demasiado pequenos: Pierden contexto necesario
- No filtrar por relevancia: Incluir documentos con baja similitud agrega ruido
- Ignorar el system prompt: Un buen system prompt guia al modelo a usar el contexto correctamente
- No manejar el caso "sin resultados": Cuando no hay documentos relevantes, el modelo debe admitirlo
Conclusion
RAG es una de las técnicas más prácticas para integrar IA en aplicaciones reales. Te permite aprovechar el poder de los modelos de lenguaje con tus propios datos, manteniendo las respuestas precisas y actualizadas.
El flujo completo es: chunking, embedding, almacenamiento, busqueda y generación. Cada paso ofrece oportunidades de optimización segun tu caso de uso específico.

Comentarios (0)
Inicia sesión para comentar